今更だけど、最近この便利さを知ったので。
Compound launch configurations とは。
.vscode/launch.json の configurations に書いてあるデバッグ設定を、複数まとめて実行 (& 終了) してくれる機能。
code.visualstudio.com
デバッグしたいアプリが、例えばフロントエンドの Javascript とバックエンドのサービス (BFF や各マイクロ サービスたち)、のように複数で構成されていて一斉にデバッグしたい時に便利。
設定方法
1. 単一フォルダーの場合
VS Code で一つのフォルダーを開いている場合は、通常のデバッグ設定と同様に .vscode/launch.json で設定する。
- まず一般的?な
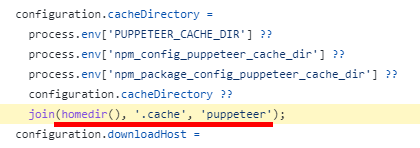
configurations (version と同じレベル) に単体でのデバッグ設定を書く。
- 次に 1. の
configurations と同じレベルに compounds と、その中にも configurations を書く。 name もつけておく。
- 最後に 1. の
configurations 内の設定のうち、一括デバッグしたいデバッグ設定の name の値を、2. の configurations の中に書いていく。
既定では一括で実行したデバッグも止める時は個別になる。止める時も一括処理で止めたい時は stopAll を true に設定しておく。
以下は .vscode/launch.json の具体例。
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
// 単体デバッグの設定
{
"name": "Launch Frontend scripts", // <-- ①の定義
"request": "launch",
"type": "msedge",
"url": "http://localhost:3000",
"webRoot": "${workspaceFolder}/public"
},
{
"name": "Launch Backend API", // <-- ②の定義
"type": "node",
"request": "launch",
"preLaunchTask": "build",
"cwd": "${workspaceFolder}",
"runtimeExecutable": "npm",
"runtimeArgs": [
"run",
"start"
],
"skipFiles": [
"<node_internals>/**"
],
"console": "integratedTerminal"
}
],
"compounds": [
{
"name": "Compound",
"configurations": [
"Launch Frontend scripts", // --> ①への参照
"Launch Backend API", // --> ②への参照
],
"stopAll": true // デバッグ終了時に一斉に止めるフラグ
}
]
}
この設定の場合、VSCode のデバッグ メニューに Compound というデバッグ設定が表示され、これを実行すると Launch Frontend scripts と Launch Backend API が同時に実行される。
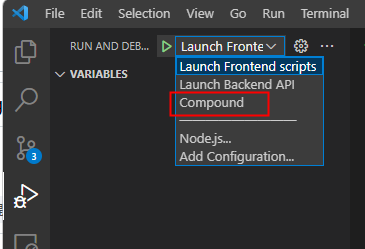
stopAll が true なので、デバッグを終了した時は一斉に止まる。
VS Code には、1 つのウィンドウで複数のフォルダー、例えばマイクロ サービスの個々のサービスを開くことができる。
その場合、ワークスペース構成を記述する、拡張子 .code-workspace のファイルにフォルダーのパス情報が 1 ないし複数記載されている。
Multi-root Workspaces *1 というらしい。
code.visualstudio.com
通常は個々のフォルダーには .vscode/launch.json があり、それぞれを一つのウィンドウで開いた時は、1. のデバッグ設定が実行できるはず。
それぞれのフォルダーで定義された個々のデバッグ設定を一つにまとめたい時は、.code-workspace の launch 要素を追加して、.vscode/launch.json と同じように compounds を記載する。
foovar.code-workspace
{
// 参照フォルダーのパス
"folders": [
{
"path": "PATH/TO/SERVICE_A"
},
{
"name": "service2", // SERVICE_B の alias みたいなもん。フォルダー名が被った時に付ける?
"path": "PATH/TO/SERVICE_B"
}
],
"launch": {
"version": "0.2.0",
"compounds": [
{
"name": "Compound",
"configurations": [
"Launch Client", // --> ①への参照
{
// --> ②への参照
"folder": "SERVICE_A", // デバッグ設定名が被った時に必要
"Launch API Server"
},
{
// --> ③への参照
"folder": "service2",
"Launch API Server"
}
],
"stopAll": true
}
]
}
}
中で参照しているデバッグ設定 Launch Client, Launch API Server は、それぞれ SERVICE_A, SERVICE_B の .vscode/launch.json で定義している設定。
PATH/TO/SERVICE_A/.vscode/launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "Launch Client", // <-- ①の定義
:
},
{
"name": "Launch API Server", // <-- ②の定義
:
}
]
}
PATH/TO/SERVICE_B/.vscode/launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "Launch API Server", // <-- ③の定義
:
}
]
}
こうやって分離しておくと、それぞれのフォルダーを開いた時は単体のデバッグができて、ワークスペースとしてまとめて開いた時はそれぞれのデバッグを一括で実行できる。
もしそれぞれのフォルダーで定義したデバッグ設定名は被った時は、
{
// --> ③への参照
"folder": "service2",
"Launch API Server"
}
みたいに、folders に書いたフォルダー名、またはそれの alias name を使って folder で指定することで、どこの Launch API Server なのかを判別する。苗字みたいなもんか *2。
注意事項
いくつか注意事項を。
その 1 - デバッグの実行順序
どうやら compounds を使って「API サーバー A が起動した後に、API サーバー B を起動して、最後に Web ブラウザーを、、、」みたいなデバッグ設定の順序を制御する方法はなさそう。
しばらく調べたけど、公式の方法は見当たらなかった。
ドキュメントにも in parallel と明記されているから、そういうもんなんだと思うことにした *3。

制御したければ何か無理やりな hack が必要なんだと思う*4。
その 2 - compounds はネスト出来ない
あるフォルダーの .vscode/launch.json で定義した compounds の設定を、別の compounds 設定から参照することができない。
これは、同じ .vscode/launch.json にかかれた compounds だろうが、.code-workspace から参照しようが関係なく、とにかくできないっぽい。
意外だったのが、2 つのフォルダーを 1 つのワークスペース .code-workspace に入れておくと、一方のフォルダーの .vscode/launch.json の compounds から、もう片方の .vscode/launch.json のデバッグ設定が参照 & 実行できたこと。
もちろん、フォルダーとして開いた時は、もう片方のフォルダーとの関係性はどこにも書かれてないので、実行はできなくなる。なので、あまり使いどころは見えてない。
まだまだ知らない便利な設定 / 機能が多い。